ESTRUCTURA DEL ÁRBOL DE DIRECTORIOS EN GNU/LINUX
Algunas distribuciones de Linux hacen modificaciones a la estructura del árbol de directorios, para adaptarlo a sus propias necesidades. De todas formas el estándar es el siguiente:

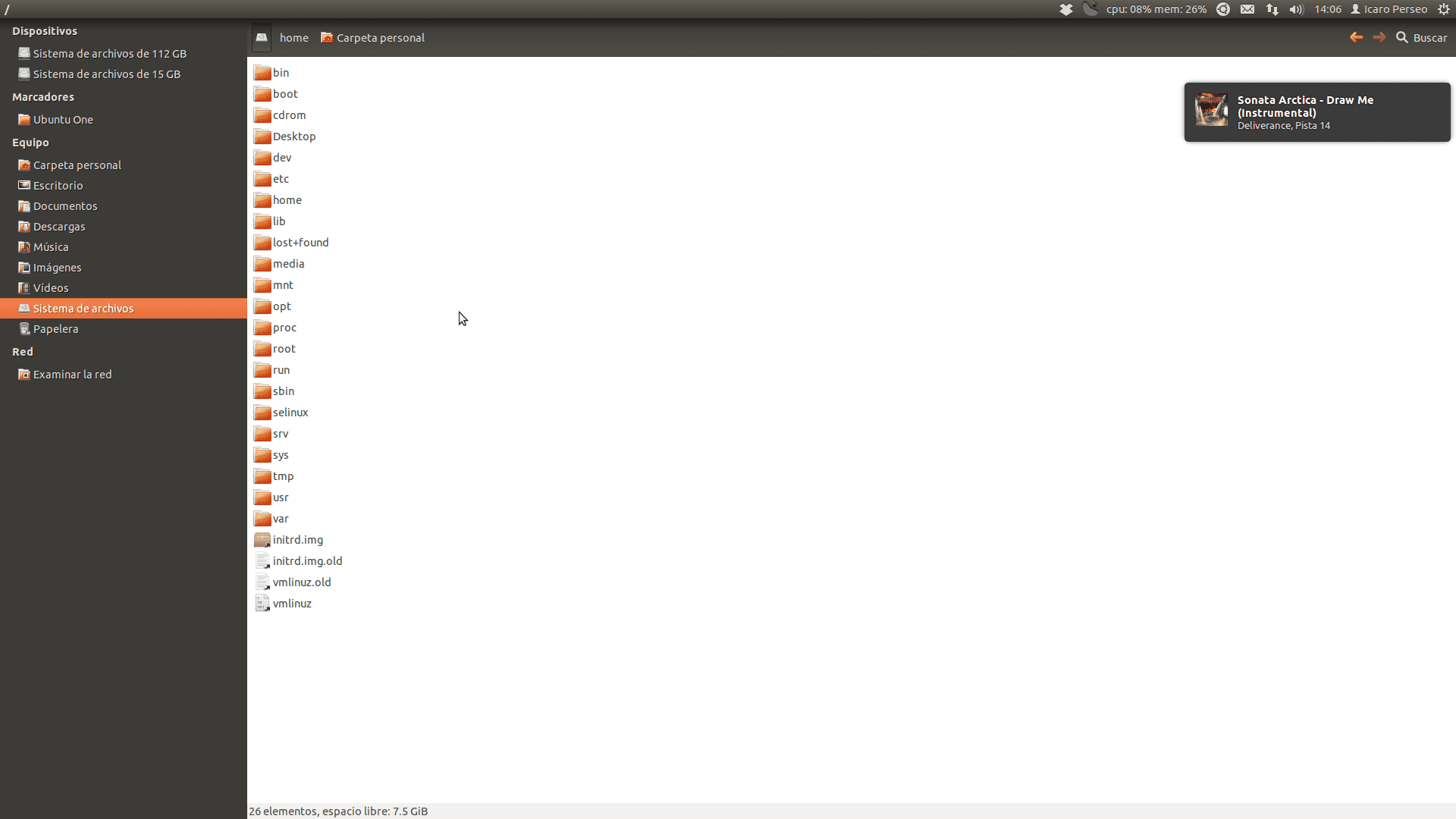
Así es como se ve en mi equipo (hasta en las capturas de escritorio reflejo mi espíritu metalero XD):

Basta de rodeos y adentrémonos en el tema…
DESCRIPCIÓN DE LA ESTRUCTURA DEL ÁRBOL DE DIRECTORIOS

<° / (raíz): Parecido a el directorio raíz “C:\” de los sistemas operativos DOS y Windows. Es el nivel más alto dentro de la jerarquía de directorios, es el contenedor de todo el sistema (accesos al sistema de archivos, incluyendo los discos extraíbles [CD’s, DVD’s, pendrives, etc.]).

<° /bin (binarios): Los binarios son los ejecutables de Linux (similar a los archivos .exe de Windows). Aquí tendremos los ejecutables de los programas propios del sistema operativo.

<° /boot (arranque): Aquí nos encontramos los archivos necesarios para el inicio de Linux, desde los archivos de configuración del cargador de arranque (Grub – Lilo), hasta el propio kernel del sistema.
Cargador de arranque (boot loader en inglés): es un programa sencillo (que no tiene la totalidad de las funcionalidades de un sistema operativo) diseñado exclusivamente para preparar todo lo que necesita el sistema operativo para funcionar.
Núcleo o kernel: es un software que constituye la parte más importante del sistema operativo. Es el principal responsable de facilitar a los distintos programas acceso seguro al hardware de la computadora o en forma básica, es el encargado de gestionar recursos, a través de servicios de llamada al sistema.

<° /dev (dispositivos): Esta carpeta contiene los dispositivos del sistema, incluso los que no se les ha asignado (montado) un directorio, por ejemplo micrófonos, impresoras, pendrives (memorias USB) y dispositivos especiales (por ejemplo, /dev/null). Linux trata los dispositivos como si fueran un fichero más para facilitar el flujo de la información.
/dev/null o null device (periférico nulo): es un archivo especial que descarta toda la información que se escribe o redirecciona en él. A su vez, no proporciona ningún dato a cualquier proceso que intente leer de él, devolviendo simplemente un EOF o fin de fichero. La forma más comúnmente utilizada es mediante la redirección, ya que /dev/null es un archivo especial y no un directorio; por lo tanto, no se pueden mover (mv) ni copiar (cp) ficheros en su interior.

<° /etc (etcétera): Aquí se guardan los ficheros de configuración de los programas instalados, así como ciertos scripts que se ejecutan en el inicio del sistema. Los valores de estos ficheros de configuración pueden ser complementados o sustituidos por los ficheros de configuración de usuario que cada uno tiene en su respectivo “home” (carpeta personal).
/etc/opt/ Archivos de configuración para los programas alojados dentro del directorio /opt.
/etc/X11/ Archivos de configuración para el X Window System, versión 11.
X: es el encargado de mostrar la información gráfica de forma totalmente independiente del sistema operativo.
/etc/sgml/ Archivos de configuración para SGML.
El lenguaje SGML: Consiste en un sistema para la organización y etiquetado de documentos. Sirve para especificar las reglas de etiquetado de documentos y no impone en sí ningún conjunto de etiquetas en especial.
/etc/xml/ Archivos de configuración para XML.
XML: Es un metalenguaje extensible de etiquetas desarrollado por el World Wide Web Consortium (W3C). Es una simplificación y adaptación del SGML. Resulta más sencillo de implementar pues evita algunas características avanzadas de SGML.

<° /home (hogar): Aquí se encuentran los ficheros de configuración de usuario así como los archivos personales del mismo (documentos, música, videos, etc.), a excepción del superusuario (administrador, root) el cual cuenta con un directorio aparte. Similar a “Mis Documentos” en Windows.

<° /lib (bibliotecas): Contiene las bibliotecas (mal conocidas como librerías) esenciales compartidas de los programas alojados, es decir, para los binarios en /bin/ y /sbin/, las bibliotecas para el núcleo, así como módulos y controladores (drivers).

<° /media (media/medios): Contiene los puntos de montaje de los medios extraíbles de almacenamiento, tales como lectores de CD-ROM , Pendrives (memoria USB), e incluso sirve para montar otras particiones del mismo disco duro, como por ejemplo, alguna partición que sea utilizada por otro sistema operativo.

<° /mnt (montajes): Este directorio se utiliza normalmente para montajes temporales de unidades. Es una directorio semejante a /media, pero es usado mayoritariamente por los usuarios. Sirve para montar discos duros y particiones de forma temporal en el sistema; no necesita contraseña, a diferencia del directorio /media.

<° /opt (opcionales): Contiene Paquetes de programas opcionales de aplicaciones estáticas, es decir, que pueden ser compartidas entre los usuarios. Dichas aplicaciones no guardan sus configuraciones en este directorio; de esta manera, cada usuario puede tener una configuración diferente de una misma aplicación, de manera que se comparte la aplicación pero no las configuraciones de los usuarios, las cuales se guardan en su respectivo directorio en /home.

<° /proc (procesos): Contiene principalmente archivos de texto, sistema de archivos virtuales que documentan al núcleo y el estado de los procesos en archivos de texto (por ejemplo, uptime, network).

<° /root (administrador): Es el /home del administrador (solo para él). Es el único /home que no está incluido -por defecto- en el directorio anteriormente mencionado.

<° /sbin (binarios de sistema):Sistema de binarios especial, comandos y programas exclusivos del superusuario (root), por ejemplo, init, route, ifup, como mount, umount, shutdown). Un usuario puede ejecutar alguno de estas aplicaciones de comandos, si tiene los permisos suficientes, o bien, si tiene la contraseña del superusuario.

<° /srv (servicios): Información del sistema sobre ciertos servicios que ofrece (FTP, HTTP…).

<° /tmp (temporales): Es un directorio donde se almacenan ficheros temporales (por ejemplo: por el navegador de internet). Cada vez que se inicia el sistema este directorio se limpia.

<° /usr (usuarios): Jerarquía secundaria de los datos de usuario; contiene la mayoría de las utilidades y aplicaciones multiusuario, es decir, accesibles para todos los usuarios. En otras palabras, contiene los archivos compartidos, pero que no obstante son de sólo lectura. Este directorio puede incluso ser compartido con otras computadoras de red local.
/usr/bin: Conjunto de ejecutables (no-administrativos para todos los usuarios) de la mayoría de aplicaciones de escritorio entre otras (por ejemplo firefox). Son de solo lectura, pero pueden tener su propia configuración para cada usuario en /home. Algunos ejecutables comparten las mismas librerías que comparten las demás aplicaciones, de manera que generalmente no hay dos librerías idénticas en un mismo sistema, lo cual ahorra memoria y proporciona más orden./usr/include: Los ficheros cabeceras para C y C++./usr/lib: Las bibliotecas para C y C++./usr/local: Es otro nivel dentro que ofrece una jerarquía parecida al propio directorio /usr./usr/sbin: Sistema de binarios no esenciales; por ejemplo, demonios para varios servicios de red. Es decir, contiene programas que no proporcionan una interfaz de usuario y generalmente se ejecutan al inicio del sistema o en ciertas circunstancias. No son directamente manejados por el usuario mientras se ejecutan, aunque sí pueden ser configurados antes de que sean ejecutados./usr/share: Archivos compartidos como ficheros de configuración, imágenes, iconos, themes, etc./usr/src: Códigos fuente de algunas aplicaciones y del kernel Linux. Al igual que /mnt, esta carpeta es manejada por los usuarios directamente para que éstos puedan guardan en él el código fuente de programas y bibliotecas y así puedan accesarlo fácilmente, sin problemas con permisos. Permite que el código fuente tenga un espacio propio, accesible pero apartado de todos los usuarios./usr/X11R6/ Sistema X Window System, Versión 11, Release 6. Este directorio se relaciona con el entorno gráfico.

<° /var (variables): Archivos variables, tales como logs, archivos spool, bases de datos, archivos de e-mail temporales, y algunos archivos temporales en general. Generalmente actúa como un registro del sistema. Ayuda a encontrar los orígenes de un problema.
/var/cache: Memoria caché de las aplicaciones, aunque también se utiliza el directorio /tmp para lo mismo./var/crash/ Se depositan datos e información, referentes a las caídas o errores del sistema operativo. Es más específico que/var en general./var/games/ Datos variables de los juegos del sistema. Este directorio no es imprescindible y muchas veces es omitido por las propias aplicaciones de juegos, pues utilizan la carpeta de usuario en/home para guardar datos variables como configuraciones, por poner un ejemplo. De todas maneras, los juegos de gnome utilizan este directorio./var/lib: Información sobre el estado actual de las aplicaciones, modificable por las propias aplicaciones./var/lock: Ficheros que se encargan de que un recurso sólo sea usado por una aplicación determinada que ha pedido su exclusividad, hasta que ésta lo libere./var/log: Es uno de los subdirectorios más importantes ya que aquí se guardan todo tipo de logs del sistema./var/mail: Buzón correos o mensajes de los usuarios. Si no utiliza cifrado, generalmente se utiliza entonces la carpeta personal para la misma labor por parte de programas que manejen correos electrónicos./var/opt: Datos usados por los paquetes almacenados en /opt./var/run: Información reciente. Trata acerca del funcionamiento del sistema desde el último arranque. Por ejemplo, los usuarios actualmente registrados o logueados, que han ingresado; y los demonios que están en ejecución./var/spool: Tareas a la espera de ser procesados (por ejemplo, colas de impresión y correo no leído)./var/tmp: Archivos temporales que, a diferencia de /tmp, no se borran entre sesiones o reinicios del sistema, pero que de todas maneras siendo prescindibles.
<° /sys (sistema): Contiene parámetros de configuración del sistema que se está ejecutando.
Sacado de: http://blog.desdelinux.net/estructura-de-directorios-en-linux/































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}